I ran into Rob Ward at a recent StartupGrind and he came across as very personable, relaxed and successful. He is a Founder at Annex Products, who make the incredibly popular Quad Lock cases for mounting smart phones on bikes, cars and people.
We caught up a few days later for a coffee near his office in Prahran. The Annex office had a cool set-up with ping-pong table, arcade machine, 3D Printer, quadcopter and lots of prototypes. His team were working behind 27-inch iMacs running Solidworks for CAD and for everything else it was the just usual Dropbox, Pages, Numbers, Adobe Creative suite and Final Cut Pro.
I intended to ask him about the different platforms they used to manage and run their business, but we spent quite a bit of time talking about sales and marketing. He sees Annex as a brand and product design business. Great design is important but “isn’t enough to stand out from the crowd”. You need good sales and marketing.
Rob learnt sales and marketing the hard way (or the best way he’d say). In the mid 90s he was out walking the streets selling OptusVision cable TV to Australians. I remember thinking that was a horrible job at the time but Rob reckons it gave him the best possible sales education. Maybe I missed out!?
The best sales and marketing tools Annex use are Facebook Ads, Email lists – “the best customers are return customers” – and AdRoll, a “retargeting” platform. Retargeting works by keeping track of people who visit your site and displaying your retargeting ads to them as they visit other sites online. That’s important because many people don’t buy the first time they visit your site. They just need a little reminding!
Some of the other key systems/platforms they use are:
Crowdsourcing:
Kickstarter: He had to perform some magic in setting up a prerequisite US Bank account to get started, but this step got the ball rolling and “proved” there was a market for their product. (The US bank account issue does not exist anymore, at least for Australians.)
eCommerce customer interface:
Shopify is the businesses storefront. Rob mentioned how easy it was to set-up and use – “Why would you build your own?”. They use Canadian developers to tailor the site (Responsive design etc.). Why Canada? Because Canada has great Liquid developers. (Liquid is a templating language for Shopify). Previously they’d sold Opena cases on a “cheaper solution” (not Shopify) and then one day Ashton Kutcher tweeted about them and knocked their system over. The ecommerce platform provider at the time gave them as much infrastructure grunt as he could and they still fell over. Shopify has never had this problem.
Payments:
Paypal and Stripe (which only just kicked off in Australia making it easier to use accept payments from anywhere in the world).
Fulfilment:
Shipwire: You previously needed a US account to get this started just like Kickstarter. It’s easier now. Shipwire integrates with Shopify, and a heap of other commerce systems. They store your products in their warehouses, provide shipping rates and inventory back to your storefront, arrange delivery etc. These guys are crucial if your business ships a physical product.
Customer Support:
Zendesk: Keeps track of customer issues and details. As the Annex business hit scale, there was no other way to keep track of this stuff.
CRM:
Capsule CRM: Annex primarily use this to manage relationships with their B2B customers.
Accounting software:
Xero: Accounting SaaS provider. Cool… but it’s still accounting.
List Management:
Mailchimp: Manage your email lists.
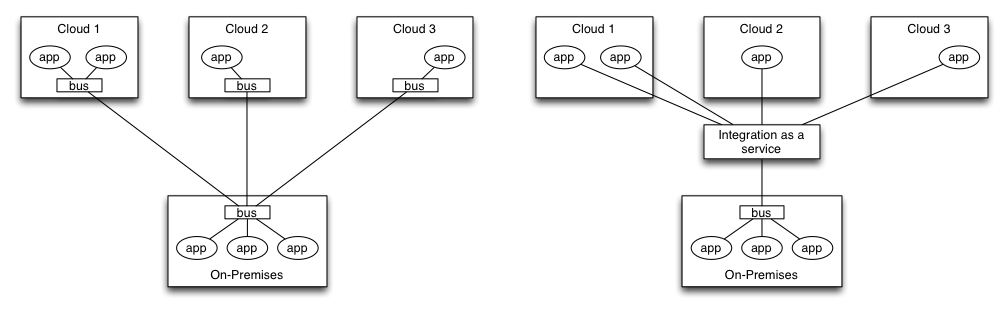
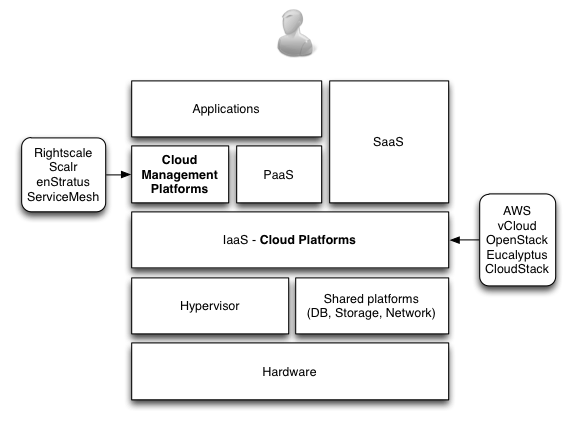
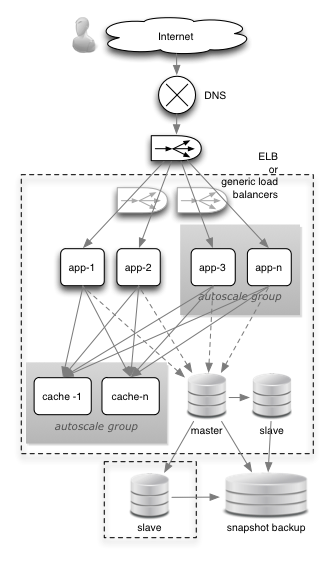
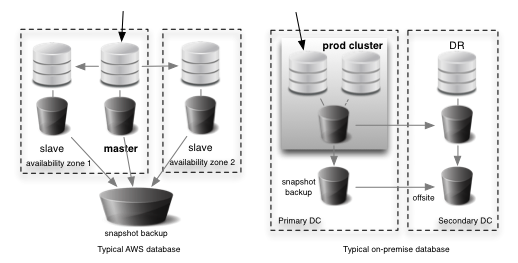
All of these platforms are software-as-a-service. The ecosystem they play in has forced the major players to integrate well with each other. This truly is a business without on-premise IT (apart from their iMacs).
Rob takes the approach of “do and change” with his business so he’s not too concerned about change. If a SaaS provider they use started to alienate their base or went out of business I imagine he’d take it in his stride and move to someone else. Possibly a few late nights and stressful moments, but Annex would get through it.
One thing he kept iterating was how easy it was to set up these businesses.
So check them out. It’s a great example of a contemporary global niche business, where the barriers to entry get lower and lower.
Start your own business. Looks easy enough!