I remember the first time I worked for IT at a bank. The language in the workplace was all about control and process and more process. My manager was a great people person, which meliorated this mechanistic tendency.
Of course having worked there for a while I realised that talk and action were somewhat different. Undocumented changes occurred and leadership turned a blind eye. Primadonna technologists roamed like cowboys across the systems. GNU tools showed up in the oddest of directory locations.
Command and control was the edict but it was like herding cats. IT was managed as one big machine (Back in the 70s when I was playing school ground tiggy it probably was one machine) that could be managed down to the smallest element. Very particular and focused.

The claw of the beast (John Christian Fjellestad via Flickr)
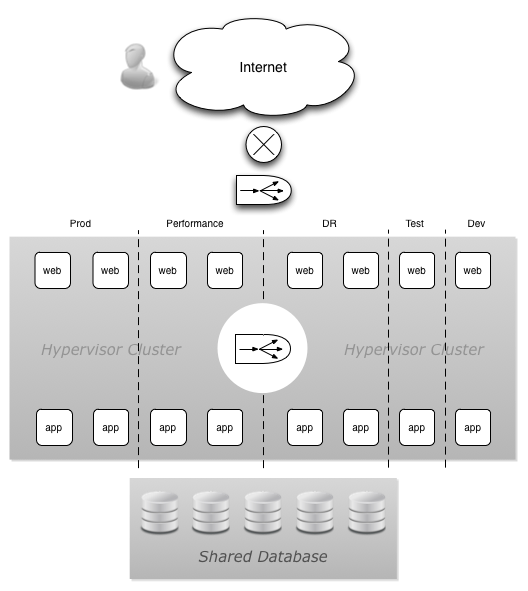
Of course IT supported only simpler applications back then like ledger accounting (urgh). Now IT underpins every part of a business. Business and IT have become one big melange.
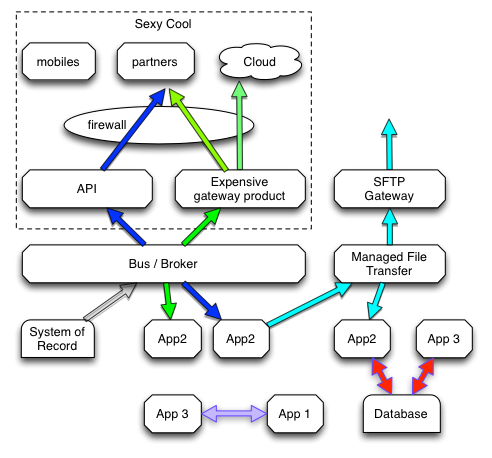
With firewall boundaries being torn down to support XaaS, mobile and 3rd party integration the world and organisations are becoming one mega-melange.
Organisations that see IT as something they can command and control are setting themselves up for disappointment, or consigning themselves to the past.
In this excellent blog Venkatesh Rao at Ribbonfarm details 8 metaphors for the modern organisation. The organisational metaphor of a machine is where we were, and the metaphor of the organisation as brain or organism is where we are heading.
You cannot control all details of an operation. A better approach is to:
- Assess and better manage risk
- Work to make IT locally and globally antifragile. Make it so IT gains from disorder.
- Any other idea comrades, add a comment.
Risk management entails making decisions moving forward but looking backward. Assessing the likelihood of something bad happening, say an AWS zone failing, or a VC-backed vendor going bankrupt, can be problematic. Assessing the MTTF of a hard drive is a little more scientific. We can apply standards, certifications etc. to technology and providers etc., but hey…. Sarbanes Oxley didn’t stop the GFC.
Another method could be to look at managing the risk through Insurance and possibly even state governments. (Socialist, eh? I saw that “comrade” earlier)
I like the idea of insurance companies and governments (ICAG) providing incentives for better IT management. ICAGs will only cover risk if there is a level of transparency, disclosure and accountability from IT users, vendors and providers. Mandatory disclosure laws are a good example – looking at you Australia. Another example could be whether an organisation’s risks should be covered if they don’t perform regular platform lifecycles.
Technology will only improve standards (security, service levels, manageability etc.) with transparency and audited action that drives improvements. Open source development is a good example of heading in the right direction. We also need to report this stuff in annual reports, marketing briefs and government audits.
In the same way that airlines and airplane-makers disclose details of accidents and implement improvements to avoid recurrences, thereby improving air travel safety every year, IT must organise itself so that it is biased to improving without the need for “top-down” intervention. Some things will slip through the cracks but the “rules” will adjust to stop the same event occurring again.
Technology users and providers that can’t adapt will die off. Those that can will thrive.
What are some open and transparent practices IT should have in place to bias it to improving over time?
(As a side note to wide-reading generalists, check out Francis Fukuyama’s The Origin of Political Order. Nation States that had the right institutions and were accountable thrived. When writing this, the same concepts came to mind.)